casimac package¶
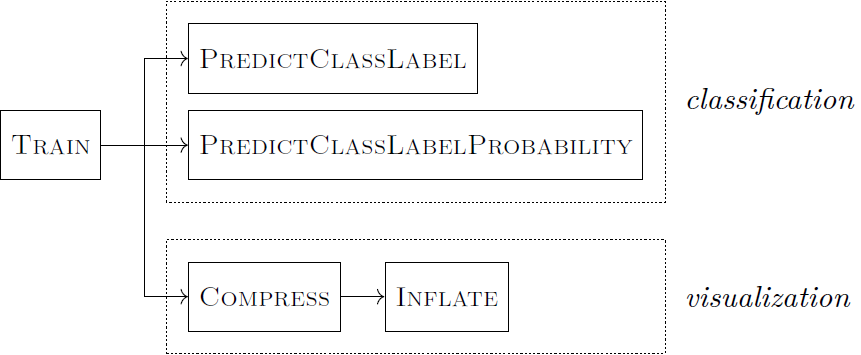
The package consists of a single class CASIMAClassifier with different use cases as shown in the sketch below. For more details about the use cases, see appendix B of arXiv:2103.02926.
- class casimac.casimac.CASIMAClassifier(model_constructor, repulsion_strength=1, repulsion_number=1, attraction_strength=0, attraction_number=1, metric='euclidean', proba_calc_method='analytical', proba_NMC=1000, p_calc_method='iterative', random_state=None, l_repulsion_reduce=<function nanmean>, l_repulsion_fun=None, l_attraction_reduce=<function nanmean>, l_attraction_fun=<ufunc 'reciprocal'>, l_c_transformation_fun=None)[source]¶
Multi-class/single-label classifier.
- Parameters:
model_constructor (callable) – Method that returns an sklearn estimator. This estimator is trained on the estimation of latent variables from features. In particular, the estimator must provide a
fitmethod (for training) and apredictmethod (for predictions). For the prediction of class probabilities, thepredictmethod must also support a second argumentreturn_std, which returns the standard deviations of the predictions together with the mean values if set to True. It is assumed that the predictions of the estimator obey a Gaussian probability distribution with the aforementioned mean and variance.repulsion_strength (float, optional (default: 1)) – Scalar strength used for the repulsion term (
beta). Should be non-negative. Choose 0 to disable repulsions.repulsion_number (int, optional (default: 1)) – Number of nearest neighbors used for the repulsion term (
k_beta).attraction_strength (float, optional (default: 1)) – Scalar strength used for the attraction term (
alpha). Should be non-negative. Choose 0 to disable attraction.attraction_number (int, optional (default: 1)) – Number of nearest neighbors used for the attraction term (
k_alpha).metric (str or callable, optional (default: 'euclidean')) – Metric options used in
sklearn.metrics.pairwise_distances. See the respective documentation for more details.proba_calc_method ('analytical', 'MC' or 'MC-fast', optional (default: 'analytical')) – Determines the method used for the prediction of class probabilities. Choose ‘analytical’ for an analytical calculation (can only be used for two classes, otherwise fall back to ‘MC’). Choose ‘MC’ for a sequential Monte Carlo implementation (slower, less memory) and ‘MC-fast’ for a simultaneous Monte Carlo implementation (faster, more memory).
proba_NMC (int, optional (default: 1000)) – Number of Monte Carlo samples (per dimension) for the prediciton of class probabilities.
p_calc_method ('iterative', 'explicit', optional (default: 'iterative')) – Determines the method for the calculation of the simplex vectors.
random_state (int, RandomState instance or None, optional (default: None)) – The random generator to use for the prediction of class probabilities. If an integer is given, a new random generator with this seed is created.
Noneleads to a newly generated seed.l_repulsion_reduce (callable, optional (default: numpy.nanmean)) – Legacy option, not recommended! Function to reduce the set of nearest neighbor distances to a single number used in the repulsion term. Note that numpy.nan may occur in the list of distances.
l_repulsion_fun (callable or None, optional (default: None)) – Legacy option, not recommended! Final function that is applied to the repulsion term. Set to
Noneto disable the function call.l_attraction_reduce (callable, optional (default: numpy.nanmean)) – Legacy option, not recommended! Function to reduce the set of nearest neighbor distances to a single number used in the attraction term. Note that numpy.nan may occur in the list of distances.
l_attraction_fun (callable or None, optional (default: numpy.reciprocal)) – Legacy option, not recommended! Final function that is applied to the attraction term. Set to
Noneto disable the function call.l_c_transformation_fun (callable or None, optional (default: None)) – Legacy option, not recommended! Optional transformtion function (e.g., for rescaling) of the latent variable coefficients. Set to
Noneto disable the function call.
- X_¶
Feature vectors in training data.
- Type:
array-like of shape (n_samples, n_features)
- y_¶
Target labels in training data.
- Type:
array-like of shape (n_samples,)
- classes_¶
Unique class labels in y_.
- Type:
array of shape (n_classes,)
- d_¶
Vector of latent variables calculated from X_ and y_.
- Type:
array-like of shape (n_samples,) or (n_samples, n_targets)
- model_¶
Instance of the model trained on the estimation of latent variables from features. Is created by the call of model_constructor.
- Type:
obj
- random_state_¶
Instance of the random state used for Monte Carlo predictions of the class probabilities.
- Type:
numpy.random.RandomState
- _calc_binary_projectors()[source]¶
Calculate binary projectors (normalized segmentation planes), which are used to obtain the decision function. They are stored in the attribute
_binary_projectorsduring a call offit.
- _calc_class_normals(n)[source]¶
Calculate class normals (i.e., the negative vertices) of an (n-1)-simplex. The results are stored in the attribute
_class_normalsduring a call offit.
- _calc_class_normals_explicit(n)[source]¶
Calculate the class normals (i.e., the negative vertices) of an (n-1)-simplex using an explicit method.
- _calc_class_normals_iterative(n)[source]¶
Calculate the class normals (i.e., the negative vertices) of an (n-1)-simplex using an iterative method.
- _calc_decision_function_grad(dmean, return_idx_col_map)[source]¶
Calculate gradient of the decision function.
- _calc_distance_features_to_class(d)[source]¶
Map from distance feature space d to class space y. Minimize distance to edge points to determine the correct classes.
- _calc_edge_distances(d)[source]¶
Calculate distances to edge points, which can be used to determine the correct classes.
- _calc_latent_coefficients(distance_to_own, distance_to_other_list)[source]¶
Calculate coefficients (combined from repulsion and attraction terms) for the transformation to the latent space. Specifically, map from the distance arrays of the own and the other class to an array of reduced distances. This mapping is performed for each class.
Notes
Nearest neighbor calculation may fail if there are not enough neighbors available.
Returned coefficients must be non-negative.
- _calc_proba(mu, sigma, return_std)[source]¶
Call suitable probability calculator depending on options.
- _calc_proba_analytical(mu, sigma, return_std)[source]¶
Calculate binary class probabilities (and their standard deviations) with analytical formulas.
- _calc_proba_grad(mu, sigma, dmu, dsigma)[source]¶
Call suitable probability gradient calculator depending on the number of classes.
- _calc_proba_grad_analytical(mu, sigma, dmu, dsigma)[source]¶
Calculate binary class probability gradients with analytical formulas.
- _calc_proba_grad_mc(mu, sigma, dmu, dsigma)[source]¶
Calculate (binary or multi-class) class probability gradients with a Monte Carlo approach.
Notes
This method is very experimental and not guaranteed to work.
A more stable method should be used instead.
- _calc_proba_mc(mu, sigma, return_std, method)[source]¶
Calculate (binary or multi-class) class probabilities (and their standard devitions) with a Monte Carlo approach.
- compress(s, tau)[source]¶
Alias for
inverse_transformwithmethod='referencefor backward compatibility, see there.
- decision_function(X, return_idx_col_map=False)[source]¶
Return the binary decision functions for the test vector X. Requires a previous call of
fit.- Parameters:
X (array-like of shape (n_samples, n_features)) – Query points where the classifier is evaluated.
return_idx_col_map (bool, optional (default: False)) – If True,
idx_col_mapis returned.
- Returns:
d (array-like of shape (n_samples,) for a binary classification or (n_sample, n_class * (n_class-1) / 2) otherwise) – Returns the decision functions in the form of an array of the form (first class index, second class index) sorted according to idx_col_map. In case of a binary classification problem, the returned array is flattened.
idx_col_map (array-like of shape (n_class*(n_class-1)/2,), optional) – List of tuples (first class index, second class index) to identify the contents of d for a multi-class classification. The indices correspond to the classes in sorted order, as they appear in the attribute
classes_. Only returned when return_idx_col_map is True and there are more than two classes. In case of two classes, idx_col_map would always correspond to ((0,1),) and is therefore not returned.
- decision_function_grad(X, return_idx_col_map=False)[source]¶
Return the gradient of the ecision function with respect to the features. Requires a previous call of
fit.Note that it is assumed that the regression model (stored in the attribute
model_) must provide a functionpredict_grad, which predicts the gradients of the predictions with respect to the features.- Parameters:
X (array-like of shape (n_samples, n_features)) – Query points where the classifier is evaluated.
return_idx_col_map (bool, optional (default: False)) – If
True,idx_col_mapis returned.
- Returns:
dd (array-like of shape (n_samples, n_fetaures) for a binary classification or (n_sample, n_features, n_class * (n_class-1) / 2) otherwise.) – Returns the gradient of the decision function with repect to the features.
idx_col_map (array-like of shape (n_class*(n_class-1)/2,), optional) – List of tuples (first class index, second class index) to identify the contents of d for a multi-class classification. Only returned when return_idx_col_map is True and there are more than two classes.
- fit(X, y, d=None)[source]¶
Fit Classifier.
Note that the estimator may depend on the naming of the labels. That is, because the set of unique labels (stored in the attribute
classes_) determines the association of classes to simplex vertices and therefore different associations lead to different latent spaces. All these latent spaces are linearly homeomorphic to each other, but can lead to a different behavior of the regression model (stored in the attributemodel_).- Parameters:
X (array-like of shape (n_samples, n_features)) – Feature vectors of training data.
y (array-like of shape (n_samples,)) – Target labels of training data.
d (latent variables, array-like of shape (n_samples, n_classes-1) or None, optional (default: None)) – Precalculated vector of latent variables. Set to
Noneto calculatedautomatically based onXandy(recommended).
- Returns:
self
- Return type:
returns an instance of self.
- fit_transform(X, y, d=None, tau=None, method='reference')[source]¶
Fit the model and transforms all latent space coordinates to another simplex space (dimensions+1). Also store the scaling factor in the attribute
tau_. Requires a previous call offit.- Parameters:
X (array-like of shape (n_samples, n_features)) – Feature vectors of training data.
y (array-like of shape (n_samples,)) – Target labels of training data.
d (latent variables, array-like of shape (n_samples, n_classes-1) or None, optional (default: None)) – Precalculated vector of latent variables. Set to
Noneto calculatedautomatically based onXandy(recommended).tau (float or None, optional (default: None)) – Scaling factor > 0. If set to
None, a data-dependent scaling is used (and returned).method ('reference' or 'scale', optional (default: 'reference')) – Determines the transformation method. ‘reference’: transformation of the simplex into rotated cones highlighting the inter-class distances (default method for visualization). ‘scale’: rescaling of the simplex to a unit simplex.
- Returns:
s (array-like of shape (n_samples, n_classes+1)) – Simplex vector space coordinates as a representation of the attribute
d_.tau (float) – Scaling factor used for the transformation. Only returned when
tauis set toNone.
- inflate(d, tau=None)[source]¶
Alias for
transformwithmethod='reference'for backward compatibility, see there.
- inverse_transform(s, tau, method='reference')[source]¶
Transform back from the transformed simplex space to the latent space. Requires a previous call of
fit.- Parameters:
s (array-like of shape (n_samples, n_classes+1)) – Reference simplex vector space coordinates to transform.
tau (float) – Scaling factor > 0.
method ('reference' or 'scale', optional (default: 'reference')) – Determines the transformation method. ‘reference’: transformation of the simplex into rotated cones highlighting the inter-class distances (default method for visualization). ‘scale’: rescaling of the simplex to a unit simplex.
- Returns:
d – Inverse transformation of the reference simplex vector space coordinates
s.- Return type:
array-like of shape (n_samples, n_classes)
- predict(X)[source]¶
Perform classification on an array of test vectors X. Requires a previous call of
fit.- Parameters:
X (array-like of shape (n_samples, n_features)) – Query points where the classifier is evaluated.
- Returns:
C – Predicted target values for X, values are from
classes_.- Return type:
ndarray of shape (n_samples,)
- predict_class_label_probability(X, return_std=False)[source]¶
Alias for
predict_probafor backward compatibility, see there.
- predict_proba(X, return_std=False)[source]¶
Return probability estimates for the test vector X. Requires a previous call of
fit.Note that it is assumed that the predictions of the regression model (stored in the attribute
model_) obey a Gaussian probability distribution. Thepredictmethod of the regression model must support a second argumentreturn_std, which returns the standard deviations of the predictions together with the mean values if set to True so that(mean, std) = model_.predict(X, return_std=True).- Parameters:
X (array-like of shape (n_samples, n_features)) – Query points where the classifier is evaluated.
return_std (bool, optional (default: False)) – If True, the standard-deviation of the predictive distribution at the query points is returned along with the mean.
- Returns:
p (array-like of shape (n_samples, n_classes)) – Returns the probability of the samples for each class in the model. The columns correspond to the classes in sorted order, as they appear in the attribute
classes_.p_std (array-like of shape (n_samples,), optional) – Best estimate of the standard deviation of the predicted probabilities at the query points. Only returned when return_std is True.
- predict_proba_grad(X)[source]¶
Return the gradient of the probability estimates with respect to the features. Requires a previous call of
fit.Note that it is assumed that the predictions of the regression model (stored in the attribute
model_) obey a Gaussian probability distribution. Thepredictmethod of the regression model must support a second argumentreturn_std, which returns the standard deviations of the predictions together with the mean values if set to True so that(mean, std) = model_.predict(X, return_std=True). Furthermore, the model must provide a functionpredict_grad, which predicts the gradients of the(mean, std)predictions from thepredictmethod with respect to the features in the same way so that(dmean, dstd) = model_.predict_grad(X, return_std=True).- Parameters:
X (array-like of shape (n_samples, n_features)) – Query points where the classifier is evaluated.
- Returns:
dp – Returns the gradient of the probability of the samples with respect to each feature for each class in the model.
- Return type:
array-like of shape (n_samples, n_features, n_classes)
- set_decision_function_request(*, return_idx_col_map: bool | None | str = '$UNCHANGED$') CASIMAClassifier¶
Request metadata passed to the
decision_functionmethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config()). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed todecision_functionif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it todecision_function.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.New in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
return_idx_col_map (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
return_idx_col_mapparameter indecision_function.- Returns:
self – The updated object.
- Return type:
object
- set_fit_request(*, d: bool | None | str = '$UNCHANGED$') CASIMAClassifier¶
Request metadata passed to the
fitmethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config()). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed tofitif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it tofit.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.New in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
d (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
dparameter infit.- Returns:
self – The updated object.
- Return type:
object
- set_inverse_transform_request(*, method: bool | None | str = '$UNCHANGED$', s: bool | None | str = '$UNCHANGED$', tau: bool | None | str = '$UNCHANGED$') CASIMAClassifier¶
Request metadata passed to the
inverse_transformmethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config()). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed toinverse_transformif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it toinverse_transform.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.New in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
method (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
methodparameter ininverse_transform.s (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
sparameter ininverse_transform.tau (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
tauparameter ininverse_transform.
- Returns:
self – The updated object.
- Return type:
object
- set_predict_proba_request(*, return_std: bool | None | str = '$UNCHANGED$') CASIMAClassifier¶
Request metadata passed to the
predict_probamethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config()). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed topredict_probaif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it topredict_proba.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.New in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
return_std (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
return_stdparameter inpredict_proba.- Returns:
self – The updated object.
- Return type:
object
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') CASIMAClassifier¶
Request metadata passed to the
scoremethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config()). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed toscoreif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it toscore.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.New in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
sample_weight (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
sample_weightparameter inscore.- Returns:
self – The updated object.
- Return type:
object
- set_transform_request(*, d: bool | None | str = '$UNCHANGED$', method: bool | None | str = '$UNCHANGED$', tau: bool | None | str = '$UNCHANGED$') CASIMAClassifier¶
Request metadata passed to the
transformmethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config()). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed totransformif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it totransform.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.New in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
d (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
dparameter intransform.method (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
methodparameter intransform.tau (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
tauparameter intransform.
- Returns:
self – The updated object.
- Return type:
object
- transform(d, tau=None, method='reference')[source]¶
Transform latent space coordinates to another simplex space (dimensions+1). Requires a previous call of
fit.- Parameters:
d (array-like of shape (n_samples, n_classes)) – Latent space coordinates to transform.
tau (float or None, optional (default: None)) – Scaling factor > 0. If set to
None, a data-dependent scaling is used (and returned).method ('reference' or 'scale', optional (default: 'reference')) – Determines the transformation method. ‘reference’: transformation of the simplex into rotated cones highlighting the inter-class distances (default method for visualization). ‘scale’: rescaling of the simplex to a unit simplex.
- Returns:
s (array-like of shape (n_samples, n_classes+1)) – Reference simplex vector space coordinates as a representation of the attribute
d_.tau (float) – Scaling factor used for the transformation. Only returned when
tauis set toNone.